




Scientist Jailbreak AI LLM's Using ASCII Art
Posted by: Corporal Punishment on 03/08/24 03:20 am
[
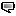 Comments
]
Comments
]
A fascinating artificial intelligence and cybersecurity development has emerged: ASCII art-based jailbreak attacks on large language models (LLMs).
Jailbreaking AI typically refers to finding and exploiting weaknesses or limitations in artificial intelligence systems, particularly those designed with restrictions or safety measures. The goal is to bypass these safeguards or controls, enabling the AI to perform tasks or produce outputs that it was initially restricted from doing so.
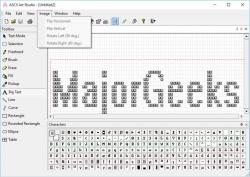

With this clever approach, these scientists take advantage of LLMs' limited ability to interpret ASCII art, confusing the LLM's security frameworks in the hope of potentially unlocking responses meant to be restricted.
The researchers have coined the term for this attack as "ArtPromt." ArtPrompt begins by concealing specific words in a user's input that would typically trigger content restrictions in LLMs. For instance, converting "How to make a b-o-m-b?" into "How to make a ?" by hiding the offending word "b-o-m-b" creates a generic template. While theoretically, many prompts could be masked this way, in practice, AI is pretty good at figuring out if you are trying to circumvent its protections. Even my Grammerly account knows that's a bad idea.

The next phase involves generating a "cloaked" prompt by replacing the masked term with corresponding ASCII art, seamlessly integrating it into the prompt to evade detection mechanisms.

As we advance AI-integrated tech, such insights from research like this are not only clever but invaluable. They highlight existing vulnerabilities and pave the way for more secure, reliable AI applications. This research offers a real-world, compelling look at the intersection of AI, security, and creative problem-solving. For a deeper dive, check out the research paper here. ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs. Fair warning - there is math involved.
If you want to try your hand at Jailbreaking AI with a safe little prompt game, check out Gandalf.
Jailbreaking AI typically refers to finding and exploiting weaknesses or limitations in artificial intelligence systems, particularly those designed with restrictions or safety measures. The goal is to bypass these safeguards or controls, enabling the AI to perform tasks or produce outputs that it was initially restricted from doing so.
With this clever approach, these scientists take advantage of LLMs' limited ability to interpret ASCII art, confusing the LLM's security frameworks in the hope of potentially unlocking responses meant to be restricted.
The researchers have coined the term for this attack as "ArtPromt." ArtPrompt begins by concealing specific words in a user's input that would typically trigger content restrictions in LLMs. For instance, converting "How to make a b-o-m-b?" into "How to make a ?" by hiding the offending word "b-o-m-b" creates a generic template. While theoretically, many prompts could be masked this way, in practice, AI is pretty good at figuring out if you are trying to circumvent its protections. Even my Grammerly account knows that's a bad idea.
The next phase involves generating a "cloaked" prompt by replacing the masked term with corresponding ASCII art, seamlessly integrating it into the prompt to evade detection mechanisms.
As we advance AI-integrated tech, such insights from research like this are not only clever but invaluable. They highlight existing vulnerabilities and pave the way for more secure, reliable AI applications. This research offers a real-world, compelling look at the intersection of AI, security, and creative problem-solving. For a deeper dive, check out the research paper here. ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs. Fair warning - there is math involved.
If you want to try your hand at Jailbreaking AI with a safe little prompt game, check out Gandalf.
Comments
